Web Scraping using Cheerio in NodeJS

Web scraping is a one way to scrap the site data and cheerio is a npm package designed using jQuery. Cheerio parses markup and provides an API for traversing/manipulating the resulting data structure. This blog will give you insight about how it's done through project I created using cheerio.
So I created a website which gives you data of all the top posts happening on subreddit. It gives you link to the post, number of upvotes it have and number of comments on the post. I used to cheerio to scrap the data from reddit.com website. Refer this documentation for basic syntax and installation of package.
1. Creating a request
We have to request with a URL of the website and this request will load the whole markup data of website in one variable using jQuery.

This will load the data in $ variable.
2. Data scraping using different attributes
Now we have to inspect and check the class/id or tag name in which data is stored we want. Ex for reddit I wanted heading of the post.
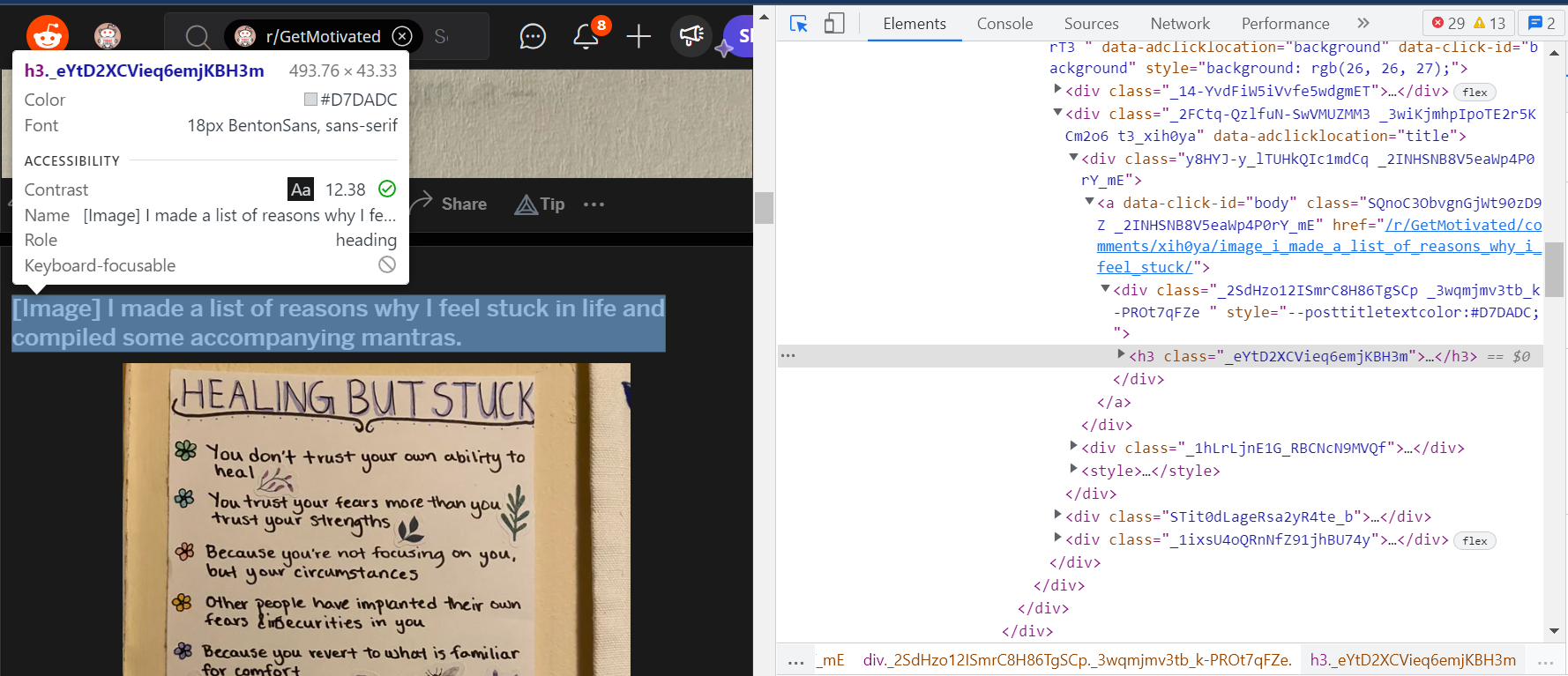 Here you can see that all the post heading are compiled in a h3 tag which has a specific class name so we can extract the heading tag using a class/tag name like this
Here you can see that all the post heading are compiled in a h3 tag which has a specific class name so we can extract the heading tag using a class/tag name like this
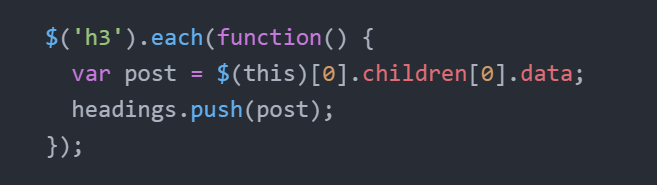
Just like that you can find anchor tag which will have link to the post in it's href attribute, same for image, video, gif, upvote number etc. I am storing all values in an array to render in a ejs file at last.
Here is a snippet of all the other needed data scrapping jQuery loops which are using name of class of the div or tag to get the data out of it.
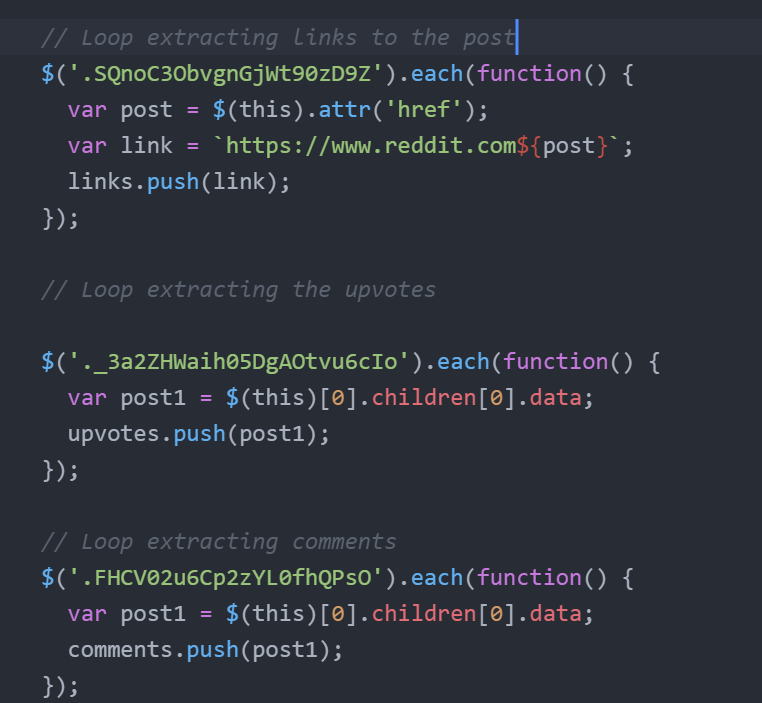
Using cheerio you can request and scrap data of any website on the internet. Here is link to my mini project you can check it out Here.
Also github repo link to check out the code of site.
Thank you so much for reading. Ishan.


